這篇文章很棒, 仔細地介紹了資料庫的種類與特性, 給在選擇應用資料庫的朋友們, 有個較為完整的概念與取捨:
https://towardsdatascience.com/choosing-the-right-database-c45cd3a28f77
簡單整理一下重點:
CAP: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
在分散式的系統架構下, 不能同時滿足這三個條件的 CAP定理:
- Consistency: 一致性, 所有分散的節點都能有一致的資料
- Availability: 可用性, 每次查詢皆可取得正確(但不一定最新)的結果.
- Partition tolerance: 分區容錯性, 部分節點異常或資料異常, 系統仍能保持運作.
(也請參考這篇: https://ithelp.ithome.com.tw/articles/10158554)
而傳統資料庫管統系統需要能滿足 ACID 的部分如下:
https://zh.wikipedia.org/wiki/ACID
- Atomicity: 原子性, 在一個交易內的異動是不會被分割的.
- Consistency: 一致性.
- Isolation: 獨立性, 在各交易操作的狀況下, 是不會互相影響的.
- Durability: 持續性, 在未異動的資料, 是能持續保持不變的.
傳統 ACID 在現代資料庫是無法同時滿足的, 所以在分散架構下的 CAP 是另一個檢視要件, 主要應用在 NoSQL 環境.
另外各式資料庫的特性如同原文介紹, 有 key-value, document, graph 不同的資料存放型態.
而其中最重要的部分是應用情境的問題:
- How many relationships are in your data?
- What is the level of complexity in your data?
- How often do the data change?
- How often does your application query the data?
- How often does your application query the relationship underlying the data?
- How often do your users update the data?
- How often do your users update the logic in the data?
- How critical is your Application in a disaster scenario?
若是能妥善理解與處理這些可能的問題, 就能找到適合的資料庫, 而實務上也是有可能互相混搭應用的, 區分為不同的資料庫應用方式, 但更重要的是適當的搭配與選擇.
繼續閱讀:
https://blog.longwin.com.tw/2013/03/nosql-db-choose-cap-theorem-2013/


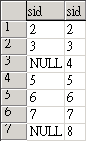
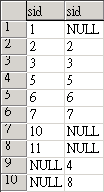
 而 right join (也就是 right outer join), 則是取出以右邊為主, 不管左邊是否存在的資料, 如:
而 right join (也就是 right outer join), 則是取出以右邊為主, 不管左邊是否存在的資料, 如: