這個管理工具, 是類似 cPanel、Plesk 這類的 hosting 服務的管理工具, 若是搭配 OpenLiteSpeed 版本的 web service 是完全免費的, 十分佛心.
而搭配 LiteSpeed 版本的 web service 的 CyberPanel Ent. 版, 在 1 domain 下, 2GB Ram 下也是每個月 0元, 可以參考價格說明:
https://cyberpanel.net/cyberpanel-enterprise/
而 OpenLiteSpeed 與 LiteSpeed Ent 版本有什麼差異, 可以參考這裡:
https://www.litespeedtech.com/products/litespeed-web-server/editions
安裝支援的系統有 Centos 7.x, Centos 8.x, Ubuntu 18.04, Ubuntu 20.04, 另外需要的條件有: Python 2.7, 1024MB or above Ram, 10GB Disk Space. 可以參考安裝說明:
https://cyberpanel.net/docs/installing-cyberpanel/
安裝完成後, 應用服務包含了 php (多版本), web, mysql, mail, ftp, dns, ssl 等, 十分方便, 另外管理介面使用 8090 port , 若希望管理介面也能用 let’s encrypt ssl 可以參考這篇的設定方式:
https://cyberpanel.net/docs/2-cyberpanel-on-ssl/
簡單說明, 也就是建立一個 website, 域名為你想用來管理的域名, 然後再到管理介面左側選單的 SSL, Hostname SSL, 選擇你想用的 website 域名後, 再按下 Issue SSL 即可.
他的 email service web 介面使用了 rainloop 也十分方便, 另外也支援了 DKIM 功能, 一樣能透過 SSL/TLS 加密 email 與使用 smtp / pop3 / imap 等方式來存取.
這個工具十分方便, 有在管理多虛擬主機的朋友們可以參考.
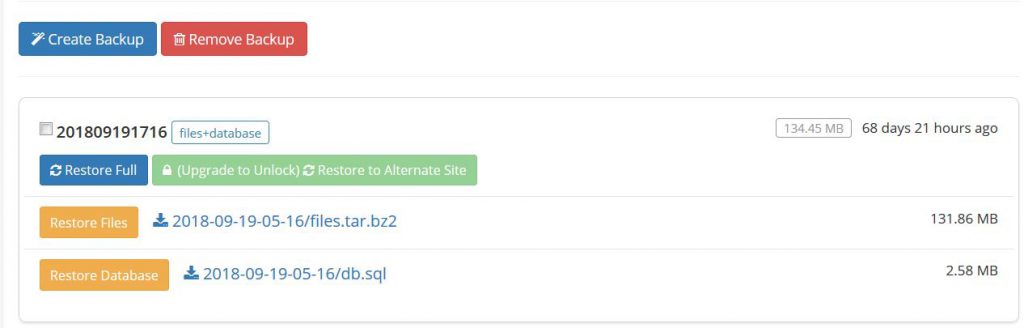
 備份管理:
備份管理: