在找負載測試工具時, 偶然間發現這個工具, k6:
可以使用開源版本自行使用, 或付費使用 cloud方案, 價格如下:
由於是全API/CLI結構, 並提供了大量的範例程式碼, 同時可以滿足壓力測試使用外, 還可以做自動化腳本測試與單元測試等功能, 十分適合開發與上線前驗測的作業與準備.
文件十分完整與容易上手:
大家可以自行測試看看.
繼續閱讀:
在找負載測試工具時, 偶然間發現這個工具, k6:
可以使用開源版本自行使用, 或付費使用 cloud方案, 價格如下:
由於是全API/CLI結構, 並提供了大量的範例程式碼, 同時可以滿足壓力測試使用外, 還可以做自動化腳本測試與單元測試等功能, 十分適合開發與上線前驗測的作業與準備.
文件十分完整與容易上手:
大家可以自行測試看看.
繼續閱讀:
今天看到一篇資料, 有關於系統上的 IOPS 成本議題, IT在設計基礎建設時, 在使用量大時, 往往會面臨效率的問題, 首當其衝的, 除了 CPU是一個關鍵外, 更多會發生的問題會在儲存的效率.
這篇資料提供了一些參加, 於取得 IOPS 的成本比較上, 不過只是參考, 因為實際上還有儲存空間的議題與系統設計架構的議題等需要考量.
請參考: http://www.dellenterprisesolution.com.tw/pc/index.html

(圖片引用自: http://www.dellenterprisesolution.com.tw/pc/index.html)
網站上線後, 需要做效能調校評估及建議, 可以使用這個 Google 的 Page Speed 效能調校建議工具:
https://developers.google.com/pagespeed/
將網址輸入後, 等待一會兒就會有資料出來, 以及許多建議讓您了解網頁效能的瓶頸所在及如何調整會更好.
測試結果如下:
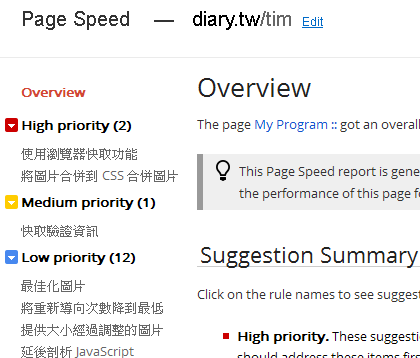 分為紅色的 High priority, 黃色的 Medium priority, 藍色的 Low priority, 另外還會有灰色的 Experimental rules, 這些讓你來進行網頁的優化調整. 當然你已經做到的他是用綠色的 Already done! 來顯示.
分為紅色的 High priority, 黃色的 Medium priority, 藍色的 Low priority, 另外還會有灰色的 Experimental rules, 這些讓你來進行網頁的優化調整. 當然你已經做到的他是用綠色的 Already done! 來顯示.
這樣的工具其實還不少, 像是這個 Pingdom Tools 有相當視覺化的呈現方式, 把頁面上每個元素的下載狀況都秀出來, 方便找出頁面上的效能問題, 和 Google Page Speed 來比的話, 前者是細部下載狀況, 找出效能瓶頸, 而後者是全面性的, 給出調整建議, 交叉使用可以更容易地將網頁效能調整好.
繼續閱讀:
http://www.smashingapps.com/2012/02/14/15-excellent-tools-for-profiling-your-websites-speed.html
最近因為有台主機的 mysql cpu 異常變高許多, 所以要來進行查詢問題所在.
因為 mysql 沒有像 mssql 的 sql profiler 那麼方便的工具, 所以利用 mysql 本身的 log 來進行, 也就是 slow query log 這個功能, 步驟如下:
1. 先將 /etc/my.cnf 中的 [mysqld] 內多加入下面資料:
log-slow-queries = /var/log/slow-query.log #slow query記錄檔的位置
long_query_time = 2 #query執行超過2秒時才記錄
2. 重啟 mysql 服務, 指令如下:
/usr/local/etc/rc.d/mysql-server restart
3. 執行一陣子後, 就可以看看該 log 檔內的 query , 接下來就是針對這些 query 來調整效能
以上是在 FreeBSD 環境下的作法. (其他環境其實也類似)
其實執行時間長不一定是效率不好, 不過若是常常發生的查詢是需要長時間的, 就有改善的必要, 簡單地說, 就是若一個查詢需要 5秒, 但一天跑不到 10次, 那根本不用管他, 不過若一個查詢需要 0.02 秒, 但一天要用到數萬次, 即使從 0.02 改善到 0.015 就會有很明顯的效能改善, 所以要看發生的頻率及所花費執行的時間, 平衡來看.
另外, 若是該 log 沒有產出, 記得權限要給對, 因為是 mysql service account 去執行寫入的動作, 就算沒有任何 log 也會有 mysql 啟動的資訊, 不會沒有任何產出的 log.
參考資料:
http://dev.mysql.com/doc/refman/5.1/en/slow-query-log.html
http://blog.lansea-chu.com/index.php/archives/238
http://homeserver.com.tw/mysql/mysql%E7%9A%84%E6%9F%A5%E8%A9%A2%E6%99%82%E9%96%93log-slow-queries/
http://ezkuan.blogspot.com/2010/05/freebsd-mysql.html
繼剛寫了Safari5發表的文章後, 想說順便跑一跑其他家的一起來拼一拼.
以下測試 ACID3 是用: http://acid3.acidtests.org/
而 javascript 效率的 Webtest 是用: http://www.101asian.com/webtest.htm
先來看看 IE9 的:
UA: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)(HTTP_USER_AGENT)
ACID3: 68分
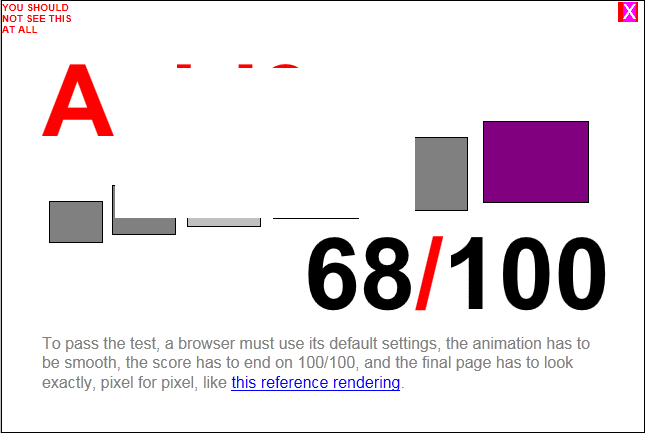 WEBTEST: 27ms
WEBTEST: 27ms
 再來是 Safari 5的:
再來是 Safari 5的:
先說好, 這篇必須是 SQL Server 2005 以上的用戶才能用到的, 因為用到的資料是 DMV 的系統 view, 也就是 Dynamic Management Views.
這裡會用到的 DMVs 是用來查詢所謂遺失的索引, 白話一點, 就是應該要建立的索引, 而沒有建立的索引, 稱之為所謂的”遺失的索引”. 資料庫在查詢時, 若是發現有這樣的狀況, 會記錄下來, 在 DMVs 內的這幾個表:
sys.dm_db_missing_index_groups
sys.dm_db_missing_index_group_stats
sys.dm_db_missing_index_details
在這些表內可以利用這篇文章 (揭露隱藏的資料以最佳化應用程式效能)的一個計算方式(當然也可以再調整), 來將影響較為嚴重而又沒有加上索引的 table 找出來, 查詢如下:
SELECT TOP 10
[Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0)
, avg_user_impact
, TableName = statement
, [EqualityUsage] = equality_columns
, [InequalityUsage] = inequality_columns
, [Include Columns] = included_columns
FROM sys.dm_db_missing_index_groups g
INNER JOIN sys.dm_db_missing_index_group_stats s
ON s.group_handle = g.index_group_handle
INNER JOIN sys.dm_db_missing_index_details d
ON d.index_handle = g.index_handle
ORDER BY [Total Cost] DESC;
這樣表列出來的資料簡單說明一下:
第一個Total Cost為總成本, 該作者是使用了一個計算的方式, 並以此為排序條件, 找出總成本最高的資料, 第二個 avg_user_impact 為對使用者的影響, 後面三個最重要了, [EqualityUsage]是指等於的條件, 例如 newsid=235 這種條件, 而 [InequalityUsage] 就是指不等的使用, 例如: newsid < 235, 而 [Include Columns]是指查詢時的涵蓋欄位, 也就是指 select newsid, newstitle, newsdesc …. from 前面的欄位.
再來談談有關索引欄位的建立, 上述的後三個欄位就都是要件, 基本上, Equality, Inequality 是指 where 使用的比較欄位, 而 Include Columns 是查詢出來的覆蓋欄位, 至於要如何下這個索引, 成本最粗的下法是將 Equality + Include Columns 加入或 Inequality + Include Columns 加入, 這樣就會有查詢較佳的效能, 但會不會是最好的, 也還是得看異動的頻繁度來考量, 而該索引有沒有價值, 也是必須要評估的, 這裡介紹的方法是將沒有建上的索引資料整理出來列表給管理員來參考用的, 可以節省許多追蹤上的時間. 希望對於效能管理上對各位能有所幫助!!
參考資料:
http://msdn.microsoft.com/zh-tw/magazine/cc135978.aspx
Apache, 用了很久, 但的確沒有好好研究過有關於 performance tuning 這塊. 事實上, 這個免費的 web server 功能真的十分強大, 尤其是可以載入的模組也多, 在使用上, 真的有許多沒有深入研究就學不到的內容.
首先我們來看有關於 MPM 的一些資料:
http://dz.adj.idv.tw/archiver/tid-214.html
在 MPM中, prefork 及 worker 是兩種不同的 multi-processing module, 在 apache 管方網站上分別有對這兩個 module 有深入的介紹:
http://httpd.apache.org/docs/2.0/mod/prefork.html
http://httpd.apache.org/docs/2.0/mod/worker.html
這二者只能擇其一來使用, 一般來說, 雖然 prefork 比較佔用記憶體, 但相容性及穩定性較佳, 也是在 FreeBSD 下安裝 Apache 的預設 MPM module.
事實上, 預設的 prefork mpm 參數如下:
<IfModule prefork.c> StartServers 5 MinSpareServers 5 MaxSpareServers 10 MaxClients 150 MaxRequestsPerChild 0 </IfModule>
之前在 用CTE來取出指定筆數 – SQL2005 這篇介紹了如何利用 CTE 來取出指定的筆數, 這篇文章將進一步實作一支 stored procedure 做為方便分頁的方式.
主要是為了方便取出指定的筆數來實作的, 所以傳入的參數很單純, 就是原本的查詢指令, 將查詢及排序條件分開, 並指定開始的索引值和結束的索引值即可, 建立的程式碼如下:
create proc sp_getRecordByCTE @sqlcmd nvarchar(4000), @ordercmd nvarchar(1000), @startindex int, @endindex int as declare @mycmd nvarchar(4000) select @mycmd = ' with myctequery as ( select row_number() over ( ' + @ordercmd + ' ) as CTESN, '+replace(@sqlcmd,'select ',' ')+' ) select * from myctequery where CTESN between ' + convert(nvarchar,@startindex) + ' and '+convert(nvarchar,@endindex) exec sp_executesql @mycmd
其中比較特別的是為了方便輸入起見, 只要將原來查詢指令的非排序部分和排序部分分開即可, 簡單範列如下:
原來的查詢是:
select a.orderid, a.orderdate, b.custname, b.custaddr from orders a inner join cust b on a.ordercustid = b.custid order by a.orderdate desc
利用上面的 stored procedure 做指定分頁的筆數若為 51~100 (每頁50筆的第二頁), 先將指令區分為紅色查詢及藍色排序, 並且如下輸入給 sp_getRecordByCTE:
exec sp_getRecordByCTE 'select a.orderid, a.orderdate, b.custname, b.custaddr from orders a inner join cust b on a.ordercustid = b.custid', 'order by a.orderdate desc', 51,100
便能將指定的分頁第二頁(51~100)這些資料取出, 這樣和使用 ADO 分頁比較, 不僅可以降低 network IO 外, 更能在複雜查詢時提升效能, 減少不必要的資源浪費, 對於網頁分頁使用時有很大的幫助. 不過目前尚有一個問題無法解決, 就是總筆數這個部分, 因為利用 ADO 查詢時, 可以取得總筆數這個資料, 利用這個 stored procedure sp_getRecordByCTE 將無法取得這個資訊, 看是否有沒有什麼好方法來做這個資料的取得及回傳, 若各位有什麼好建議也歡迎給我建議!
希望這個 stored procedure 對各位能有所幫助.
繼續閱讀: