從 MS SQL 2005 起, 支援了 CTE (Common Table Expression) 語法, 可以參考之前的文章: https://diary.tw/archives/339 .
今天要來介紹的是有關應用在遞迴方面的查詢, 利用這種查詢, 可以很容易地將資料展開, 例如像是組織圖, 或是像分類項含有子分類這樣的樹狀資料, 當然, 簡單一點的像是累加也是一樣的, 先來介紹 CTE 用在累加的語法上.
WITH cte (num, mysum) AS ( SELECT 1 as num, 1 as mysum UNION ALL SELECT num + 1, mysum + num + 1 FROM cte a where num <10 ) SELECT * FROM cte
看好, 在括號內的第一個 SELECT 1, 1 的部分, 就是原始值, 而後面的 SELECT .. FROM cte 則是開始自己對自己查詢, 最後的 num < 10 是他的 boundary condition, 也就是只做到 num < 10.
結果如下:
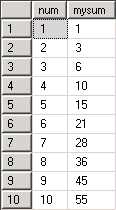 是的, 結果就是那個 1 + 2 + 3 + … + 10 = 55 .
是的, 結果就是那個 1 + 2 + 3 + … + 10 = 55 .
再來看看其他的用法, 像是分類含有子分類的資料, 先來準備一些資料:
CREATE TABLE CATEGORY (CID int primary key, NAME nvarchar(200), PARENTID int) INSERT INTO CATEGORY values (1, N'交通工具', 0), (2, N'陸上', 1), (3, N'水上', 1) INSERT INTO CATEGORY values (4, N'機車', 2), (5, N'汽車', 2), (6, N'輪船', 3) INSERT INTO CATEGORY values (7, N'空中', 1), (8, N'飛機', 7), (9, N'直升機', 7)
來組合吧, 使用CTE:
WITH CTE (CID, NAME, PARENTID, LEVEL) AS ( SELECT CID, NAME, PARENTID, 0 FROM CATEGORY WHERE PARENTID = 0 UNION ALL SELECT A.CID, A.NAME, A.PARENTID, LEVEL + 1 FROM CATEGORY A INNER JOIN CTE B ON A.PARENTID = B.CID ) SELECT * FROM CTE
結果如下:
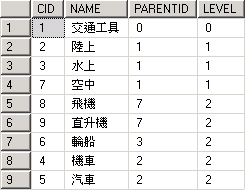
是不是很清楚看出來各分類的位階(LEVEL)狀況? 十分方便好用的語法. 再來看看如何展開成一行資料, 也就是各自分類結構合成一筆結果, 語法如下:
WITH CTE (CID, NAME, PARENTID, LEVEL, ORICID, DATA) AS ( SELECT CID, NAME, PARENTID, 0, CID, CONVERT(NVARCHAR(MAX), NAME) FROM CATEGORY WHERE PARENTID = 0 UNION ALL SELECT A.CID, A.NAME, A.PARENTID, LEVEL + 1, A.CID, DATA + '-' + A.NAME FROM CATEGORY A INNER JOIN CTE B ON A.PARENTID = B.CID ) SELECT * FROM CTE
結果如下:
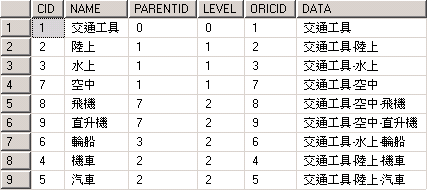
最後面的那個欄位就是想要呈現出來的結果, 說穿了, 就是一直累加上去, 只是是字串的累加(DATA), 不是數字的累加, 另外也多了一個欄位用來表現原本自己的CID(ORICID), 這樣看起來也就更清楚完整, 利用這樣的方式來表現分類結構, 非常好用呢!
另外記得字串累加的部分, 使用 NVARCHAR(MAX) 以避免發現 CTE 和累加的欄位不一致的問題, 這是要特別注意的地方.
無法對齊欄位的錯誤訊息為:
Types don’t match between the anchor and the recursive part in column “xx” of recursive query “xx”.
可以參考這篇解答: http://stackoverflow.com/questions/1838276/cte-error-types-dont-match-between-the-anchor-and-the-recursive-part
結論, CTE的遞迴語法, 其實也就是自己再對自己查詢, 只要把握好起始條件, 還有遞迴的終止條件, 就可以很順利的產出你要的結果. 大家可以多加利用這個好用的語法, Let’s CTE!!