來寫個中油油價取得.
不過一開始原以為這頁是利用靜態的內容產出的 table:
https://www.cpc.com.tw/historyprice.aspx?n=2890
利用 beautifulsoup 時, 使用 selector 雖然可以找到對應的 element, (table#tbHistoryPrice), 但找不到該 table 以下的 tr, td 對 element, 所以無法透過 select 解析並取出資料.
於是仔細看了一下 html source code, 發現原來只有一個空的 table, 而沒有內容, 而表格內容利用是 javascript 動態生成的, 而資料來源仍為靜態的 javascript 中的變數 (pieSeries), 這樣就好解決了.
利用 python 中的 regular expression 與 json 解析來直接取出該變數, 內容就更方便了. (不用解析 html element, 純文字解析)
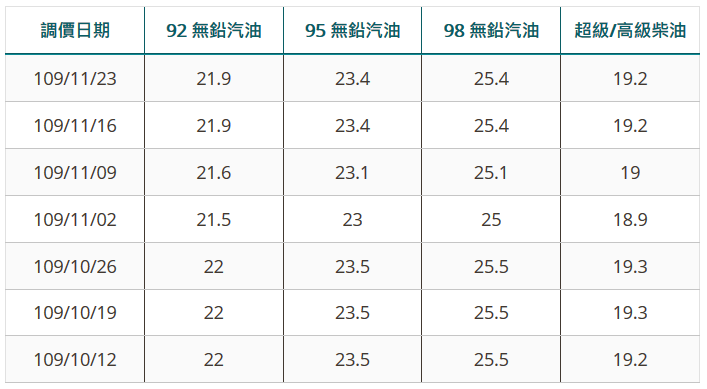
該變數內容為:
[{"name":"109/10/12","data":[{"name":"92 無鉛汽油","y":22.0},{"name":"95 無鉛汽油","y":23.5},{"name":"98 無鉛汽油","y":25.5},{"name":"超級/高級柴油","y":19.2}]},{"name":"109/10/19","data":[{"name":"92 無鉛汽油","y":22.0},{"name":"95 無鉛汽油","y":23.5},{"name":"98 無鉛汽油","y":25.5},{"name":"超級/高級柴油","y":19.3}]},{"name":"109/10/26","data":[{"name":"92 無鉛汽油","y":22.0},{"name":"95 無鉛汽油","y":23.5},{"name":"98 無鉛汽油","y":25.5},{"name":"超級/高級柴油","y":19.3}]},{"name":"109/11/02","data":[{"name":"92 無鉛汽油","y":21.5},{"name":"95 無鉛汽油","y":23.0},{"name":"98 無鉛汽油","y":25.0},{"name":"超級/高級柴油","y":18.9}]},{"name":"109/11/09","data":[{"name":"92 無鉛汽油","y":21.6},{"name":"95 無鉛汽油","y":23.1},{"name":"98 無鉛汽油","y":25.1},{"name":"超級/高級柴油","y":19.0}]},{"name":"109/11/16","data":[{"name":"92 無鉛汽油","y":21.9},{"name":"95 無鉛汽油","y":23.4},{"name":"98 無鉛汽油","y":25.4},{"name":"超級/高級柴油","y":19.2}]},{"name":"109/11/23","data":[{"name":"92 無鉛汽油","y":21.9},{"name":"95 無鉛汽油","y":23.4},{"name":"98 無鉛汽油","y":25.4},{"name":"超級/高級柴油","y":19.2}]}]
程式碼如下:
import requests
import re
import json
url = "https://www.cpc.com.tw/historyprice.aspx?n=2890"
resp = requests.get(url)
m = re.search("var pieSeries = (.*);", resp.text)
jsonstr = m.group(0).strip('var pieSeries = ').strip(";")
j = json.loads(jsonstr)
#print(j)
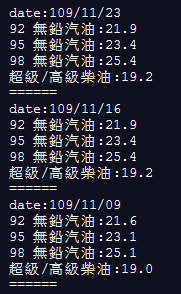
for item in reversed(j):
print("date:" + item['name'])
for data in item['data']:
print(data['name'] + ":" + str(data['y']))
print("======")
程式碼簡單說明:
- 利用 requests 來取得對應網址內容
- 利用 re 解析出 pieSeries 變數
- 利用 json.loads 載入與解析該變數內的 json
- 利用 reversed 反轉了排序(原內容由舊到新, 利用這個改為由新到舊)
- 第一層的 name 為日期, 後面再接一層 array data 其中的 name 為產品名, 而 y 為單價.
來看看執行結果吧:
https://repl.it/@timhuangt/CPCPrice
PS: 雖然解析不難, 不過因為該內容為動態的, 並非供應的資料集, 若是未來該頁面的呈現方式改變, 也無法解正常的解析囉.
[2020/11/30 23:40]
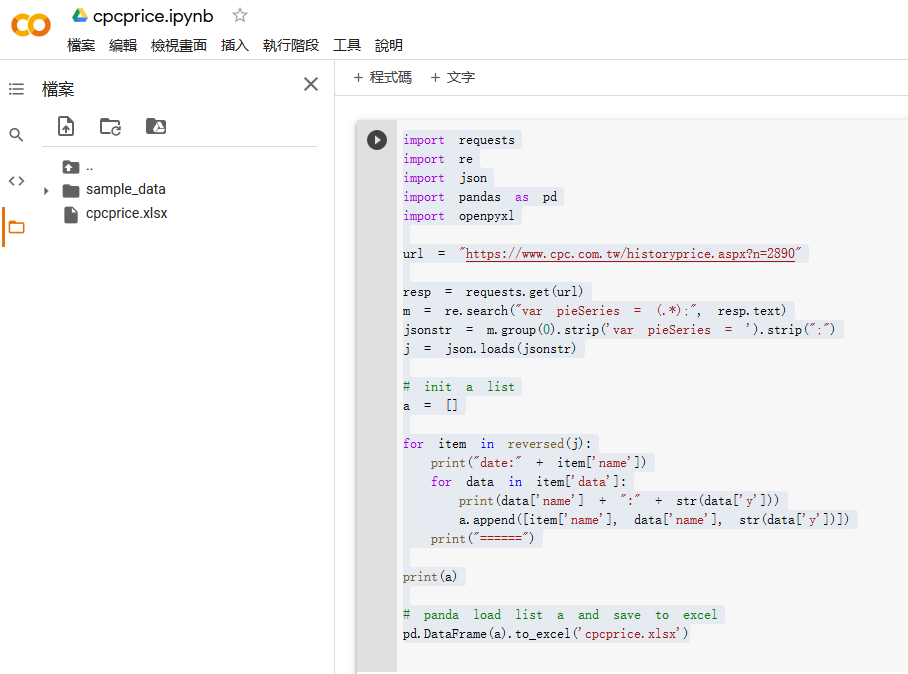
朋友問到有關如何將結果導出為 excel 檔案( .xlsx), 可以利用 pandas (https://pandas.pydata.org/) 的 dataframe 中的 to_excel 來達成, 不過由於 repl.it 服務雖然可以產出對應的 xlsx 但無法下載, 改用 google 的 colab 來實現的話, 生成的 excel 是可以下載的, 程式碼如下:
import requests
import re
import json
import pandas as pd
import openpyxl
url = "https://www.cpc.com.tw/historyprice.aspx?n=2890"
resp = requests.get(url)
m = re.search("var pieSeries = (.*);", resp.text)
jsonstr = m.group(0).strip('var pieSeries = ').strip(";")
j = json.loads(jsonstr)
# init a list
a = []
for item in reversed(j):
print("date:" + item['name'])
for data in item['data']:
print(data['name'] + ":" + str(data['y']))
a.append([item['name'], data['name'], str(data['y'])])
print("======")
print(a)
# panda load list a and save to excel
pd.DataFrame(a).to_excel('cpcprice.xlsx')
其中在第二層 for 迴圈, 新增了資料至 a list 中, 並利用了 panda dataframe 載入該 a list 後, 再利用 to_excel 即可生出 excel 檔案. 檔案可以利用左側的檔案管理功能取得, 並下載, 如下圖所示:
快來試看看吧: https://colab.research.google.com/drive/1tUuPZObhJFglJ-FZshDUrIgXEWj9-0AC
[2020/12/1 23:10]
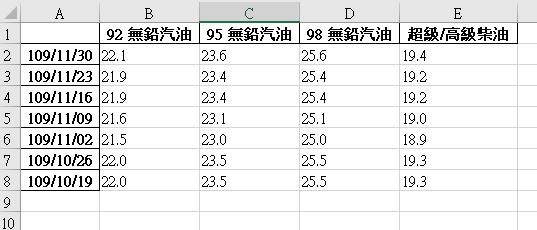
若是希望呈現方式如同原本中油網頁上的表格, 也就是 row name是日期, column name為油種, 表格內的值為油價要怎麼做呢?
很簡單, 只需要在建立 dataframe 時, 使用 at[row, col] 方式給值即可, 前面產生的 a list 不變, 而生成另一新的 dataframe 後, 再存回 excel, 程式碼如下:
# another type of excel with date as row and product as column price list
df = pd.DataFrame()
for item in a:
df.at[item[0], item[1]] = item[2]
df.to_excel('cpcdataprice.xlsx')
會再產生另一 excel 檔(cpcdataprice.xlsx), 內容如下:
程式碼一樣放在原本的 colab 同一支程式中:
https://colab.research.google.com/drive/1tUuPZObhJFglJ-FZshDUrIgXEWj9-0AC
參考資料:
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html