隨著 html5 的發展, 這個可以在線上製作 html5 的動畫工具, 可以讓大家在製作簡單動畫上有更容易的方式, 網址: https://www.mugeda.com/
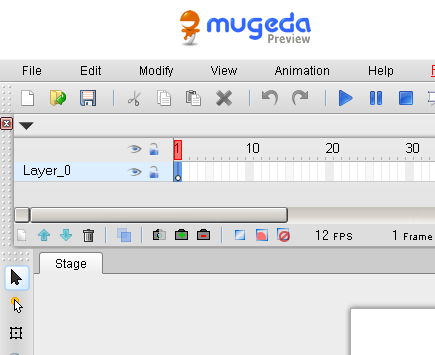
這個 Mugeda 網站, 利用線上編輯的方式, 讓大家可以直接製作動畫, 並且可以直接嵌入網站(使用方式為 iframe), 而編輯介面也是像 flash 等軟體一樣, 利用影格編輯的方式來操作:
這裡有在 mugeda 製作的熱門動畫, 可以參考看看: https://www.mugeda.com/popular
隨著 html5 的發展, 這個可以在線上製作 html5 的動畫工具, 可以讓大家在製作簡單動畫上有更容易的方式, 網址: https://www.mugeda.com/
這個 Mugeda 網站, 利用線上編輯的方式, 讓大家可以直接製作動畫, 並且可以直接嵌入網站(使用方式為 iframe), 而編輯介面也是像 flash 等軟體一樣, 利用影格編輯的方式來操作:
這裡有在 mugeda 製作的熱門動畫, 可以參考看看: https://www.mugeda.com/popular
在開發網頁程式, 用到解析和產生 JSON 是經常發生的事, 不過如何快速的解析或是產生 JSON , 又或是用來除錯這些 JSON 的資料, 不像 XML 可以利用瀏覽器來幫忙, JSON 可以利用這個作者 Thomas – http://www.thomasfrank.se/about.html 開發的工具來進行 JSON 的線上測試.
說明在這裡: http://www.thomasfrank.se/json_editor.html
他有線上使用版, 和下載版, 若是進行除錯, 可以直接使用線上版: http://www.thomasfrank.se/downloadableJS/JSONeditor_example.html
以之前文章 https://diary.tw/archives/285 的資料為例:
{ 'obj1': {
'child1':'value1',
'child2':'value2'
},
'array1': [1, 2, 3, 4, 5]
};
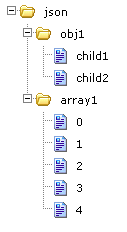
將內容貼到 JSON Editor 裡, 按下 save 鍵, 就會產生出該 JSON 的樹狀結構在該 editor 左側(記得要自己按下 + 號展開, 如下圖:
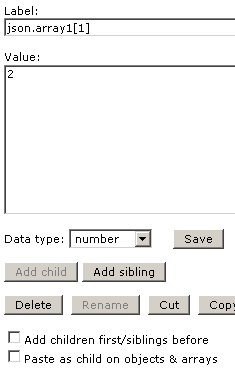
 這樣可以很容易的理解及看出該 JSON 資料的內容. 若是要取得某一節點, 可以點在該節點上, 並看 editor 上的 label及下面的 value 就可以利用程式取出該 JSON 資料結構的資料點, 以上面的 array1 中的 1 為例, 圖示如下:
這樣可以很容易的理解及看出該 JSON 資料的內容. 若是要取得某一節點, 可以點在該節點上, 並看 editor 上的 label及下面的 value 就可以利用程式取出該 JSON 資料結構的資料點, 以上面的 array1 中的 1 為例, 圖示如下:
這樣是不是十分方便, 對於在使用 JSON 的開發上, 有十足的加速作用呢!
這個網站, 是個 Geek Calender – http://technet.tw/ , 很有意思, 是程式/設計用的宅民曆.
內容除了原本的國曆及農曆外, 還有仿傳統農民曆用的”宜”, “忌”等與程式/設計相關的事情, 而且更有意思的, 是下面的”程式小格言” 呢.
圖片引用自該網站:

每天都可以來看看, 是不是適合寫程式/設計!
從狂人那裡看來的: http://briian.com/?p=6278
這個 Print Friendly 網頁工具, 利用 bookmarklet 的方式, 分析網頁結構後, 讓原本列印網頁, 會將許多不必要的區域, 像是廣告或是與文章內容無關的地方刪去, 節省列印的耗材及增進容易閱讀的功能, 這真是個方便好用的網頁服務.
網址在: http://www.printfriendly.com/
可以直接將它提供的 bookmarklet 拖拉到書籤, 在瀏覽網頁時, 點擊即可產生整理好要列印的版本, 或是在上面的網頁上貼上想列印的網頁的網址也可以. (前者更為方便好用)
大部分的新聞網站其實都有提供列印按鈕, 少數的沒有, 即使沒有也沒關係, 只要有這個 PrintFriendly 的 bookmarklet 也可以很容易地達到這個功能.
另外它也提供給網站發佈者一個 widget 的功能, 可以自訂列印網頁的按鈕, 方便給網頁發佈者放在網站上, 給來訪的訪客列印之用, 真的還蠻不錯的呢. (從這裡進入: http://www.printfriendly.com/button )
另外也有轉出 pdf 及 email 的功能, 真是好用!
一般在 SQL Server 中, 若要找某 table 中的 identity 最後值(最大值或目前值), 可以使用以下指令:
dbcc checkident('table_name', NORESEED)
可以參考之前的這篇文章: SQL Server的Identity欄位使用/複製/重設 – https://diary.tw/archives/457
不過, 若是 table 很多, 又想一次性的將各 table 中的 identity 欄位最後值找出, 可以利用系統資料表: sys.identity_columns (2005, 2008, 2008R2都有) 來查找, 配合 sys.objects 表, 可以一次將 table, column, 最後值(last_value) 查找出來, 如下:
select b.name, a.name, a.last_value from sys.identity_columns a inner join sys.objects b on a.object_id=b.object_id
這樣可以利用一個指令就將該資料庫中的所有資料表含有 identity 欄位的最後值, 若是只需要使用者自行定義的 table (不要含系統表), 可以多加上 b.type=’U’ 來進行過濾.
參考資料:
http://technet.microsoft.com/zh-tw/library/ms176057.aspx
http://msdn.microsoft.com/en-us/library/ms187334.aspx
aws (amazon web service) 終於有自己的 route53 管理介面了(console).

以往要管理 route53, 要嘛就是用 api (http://docs.amazonwebservices.com/Route53/latest/APIReference/), 不然要 ui 的管理介面就得用 3rd party 的 DNS30: http://www.dns30.com/, 對於不熟悉的人來說, 還真的不太方便.
現在 aws 推出了 route53 的管理介面了, 真的可以方便在使用 route53 服務操作上, 利用友善的管理介面, 無論是在新增修改管理上, 都更加的方便了呢!
有在使用的朋友們, 可以快去試看看: https://console.aws.amazon.com/route53/home
使用正則表示法來表示一個 ip 區間, 例如: 1.2.3.1~64 這樣的表示方式為:
^1\.2\.3\.([1-9]|[1-5][0-9]|6[1-4])$
另外也會有這樣的寫法: (下面是”流量的秘密”這本書中的第246頁寫的, 不過比較有效率的寫法應為上面, 實際上使用最後的 google analytics 的說明幫助頁上產生的亦同上)
^1\.2\.3\.([1-9]|[1-5][0-9]|[1-6][1-4])$
這是因為在 google-analytics中, 若需要新增設定檔用來排除某 ip, 或某區段 ip 時會用到, 如下畫面:
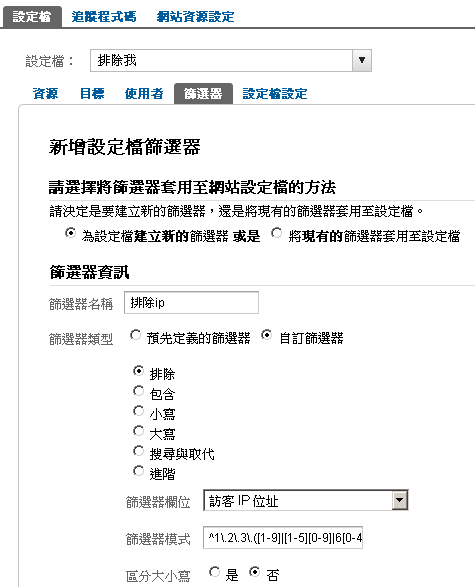 這樣可以很方便的進行某區段的 ip 篩選, 其實 google analytics 的說明幫助頁也有這個功能, 很方便, 自動可以產生某區段 ip 的正則表示法(或稱規則運算式): https://www.google.com/support/googleanalytics/bin/answer.py?answer=55572&hl=zh_TW&utm_id=ad
這樣可以很方便的進行某區段的 ip 篩選, 其實 google analytics 的說明幫助頁也有這個功能, 很方便, 自動可以產生某區段 ip 的正則表示法(或稱規則運算式): https://www.google.com/support/googleanalytics/bin/answer.py?answer=55572&hl=zh_TW&utm_id=ad
若需要試看看對不對, 可以利用線上工具來測試: http://www.regexplanet.com/simple/index.html.
Firefox 7.0 才更新到 7.0.1, 現在來 8.0 了啊. 介面又有些調整了, 速度感覺有心理上的作用那麼快一點, 跑一下 Acid3 Test (http://acid3.acidtests.org/)是 100, 而且速度還蠻快的.

新功能參考如下: (引用自: http://moztw.org/firefox/releases/8.0/ )
在用 firefox 的朋友們, 快來更新囉!
前一陣子已經有不少人開始使用 google analytics 的即時報表了, 這個還在 Beta 階段的即時網站資訊統計報表功能, 真的很強大.
簡單地說, 原本大約是半天到1天時間差的報表統計資訊, 往往需要等上一陣子才會有報表, 但現在這個即時報表, 可以將現在當下的網站流量狀況即時呈現, 讓人在第一時間就取得目前網站的即時資訊, 真的很好用.
不過這種即時報表, 在以往是許多付費統計網站功能, 不過 Google 提供了免費的即時報表功能, 相信會打到不少原本在靠這個賺錢的網站.
不論流量大小的網站, 若要經營, 這樣的即時報表對於有活動在進行的狀況下, 是非常重要的情報, 而且可以快速地反應及操作活動的調整, 以期能有更好的效果.
有在用 Google analytics 的朋友們, 可以快去試看看!
這個時間差計算機是因為最近在查圖表中的流量計算使用, 由於 cacti 圖表可以自行放大想看的區間, 若是要將頻寬換成流量, 要把圖表的起迄時間算出來, 利用平均頻寬再乘上時間差, 就可以算出流量, 例如:
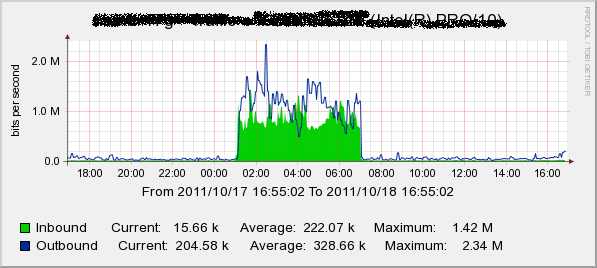
這張圖來看, 是剛好一天的流量, 在未放大時, 很好計算, 一天的流量 outbound 是 328.66kbps * 86400 seconds = 27Mbits = 3.385MBytes
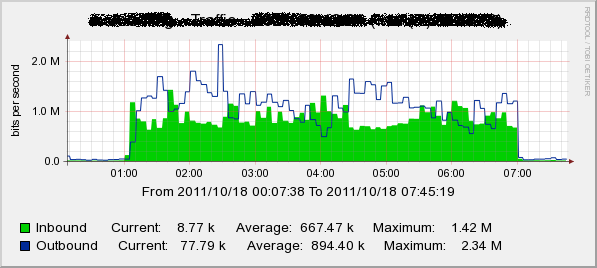 這張圖則是放大後來看, 時間是 2011/10/18 00:07:38~2011/10/18 07:45:19 , 利用這個時間差計算機來算: http://sample.diary.tw/timediff/ 可得 27461 秒, outbound 流量則為 894.40kbps * 27461 seconds = 23.42Mbits = 2.928MBytes
這張圖則是放大後來看, 時間是 2011/10/18 00:07:38~2011/10/18 07:45:19 , 利用這個時間差計算機來算: http://sample.diary.tw/timediff/ 可得 27461 秒, outbound 流量則為 894.40kbps * 27461 seconds = 23.42Mbits = 2.928MBytes
可以看得出來, 主要的 outbound 流量集中的下面放大的這個時間區段.
有時候要計算這個小時間差, 雖然紙筆很方便, 但是數量一多就不好算了, 所以寫個小程式用來計算使用, 這個程式利用了 jQuery, jQuery UI, 和 Timepicker to jQuery UI – http://trentrichardson.com/examples/timepicker/ 來達成, 計算的方式是使用 javascript 來計算, 所以是利用 Date 的 parse() 來將日期時間轉為 milliseconds, 再來計算兩個時間差, 就可以得到計算的結果, 如下:
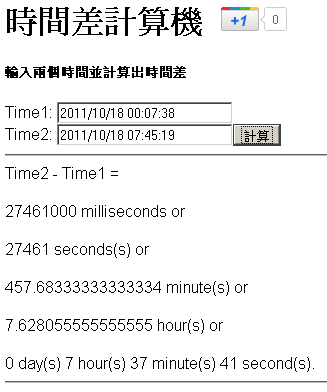
若實用或方便的話, 請多多利用. 網址: http://sample.diary.tw/timediff/